

How To Do A Sitemap Audit For Better Indexing & Crawling Via Python via @sejournal, @KorayGubur

Sitemap auditing involves syntax, crawlability, and indexation checks for the URLs and tags in your sitemap files.
A sitemap file contains the URLs to index with further information regarding the last modification date, priority of the URL, images, videos on the URL, and other language alternates of the URL, along with the change frequency.
Sitemap index files can involve millions of URLs, even if a single sitemap can only involve 50,000 URLs at the top.
Auditing these URLs for better indexation and crawling might take time.
But with the help of Python and SEO automation, it is possible to audit millions of URLs within the sitemaps.
What Do You Need To Perform A Sitemap Audit With Python?
To understand the Python Sitemap Audit process, you’ll need:
- A fundamental understanding of technical SEO and sitemap XML files.
- Working knowledge of Python and sitemap XML syntax.
- The ability to work with Python Libraries, Pandas, Advertools, LXML, Requests, and XPath Selectors.
Which URLs Should Be In The Sitemap?
A healthy sitemap XML sitemap file should include the following criteria:
- All URLs should have a 200 Status Code.
- All URLs should be self-canonical.
- URLs should be open to being indexed and crawled.
- URLs shouldn’t be duplicated.
- URLs shouldn’t be soft 404s.
- The sitemap should have a proper XML syntax.
- The URLs in the sitemap should have an aligning canonical with Open Graph and Twitter Card URLs.
- The sitemap should have less than 50.000 URLs and a 50 MB size.
What Are The Benefits Of A Healthy XML Sitemap File?
Smaller sitemaps are better than larger sitemaps for faster indexation. This is particularly important in News SEO, as smaller sitemaps help for increasing the overall valid indexed URL count.
Differentiate frequently updated and static content URLs from each other to provide a better crawling distribution among the URLs.
Using the “lastmod” date in an honest way that aligns with the actual publication or update date helps a search engine to trust the date of the latest publication.
While performing the Sitemap Audit for better indexing, crawling, and search engine communication with Python, the criteria above are followed.
An Important Note…
When it comes to a sitemap’s nature and audit, Google and Microsoft Bing don’t use “changefreq” for changing frequency of the URLs and “priority” to understand the prominence of a URL. In fact, they call it a “bag of noise.”
However, Yandex and Baidu use all these tags to understand the website’s characteristics.
A 16-Step Sitemap Audit For SEO With Python
A sitemap audit can involve content categorization, site-tree, or topicality and content characteristics.
However, a sitemap audit for better indexing and crawlability mainly involves technical SEO rather than content characteristics.
In this step-by-step sitemap audit process, we’ll use Python to tackle the technical aspects of sitemap auditing millions of URLs.
 Image created by the author, February 2022
Image created by the author, February 20221. Import The Python Libraries For Your Sitemap Audit
The following code block is to import the necessary Python Libraries for the Sitemap XML File audit.
import advertools as adv
import pandas as pd
from lxml import etree
from IPython.core.display import display, HTML
display(HTML("<style>.container { width:100% !important; }</style>"))
Here’s what you need to know about this code block:
- Advertools is necessary for taking the URLs from the sitemap file and making a request for taking their content or the response status codes.
- “Pandas” is necessary for aggregating and manipulating the data.
- Plotly is necessary for the visualization of the sitemap audit output.
- LXML is necessary for the syntax audit of the sitemap XML file.
- IPython is optional to expand the output cells of Jupyter Notebook to 100% width.
2. Take All Of The URLs From The Sitemap
Millions of URLs can be taken into a Pandas data frame with Advertools, as shown below.
sitemap_url = "https://www.complaintsboard.com/sitemap.xml"
sitemap = adv.sitemap_to_df(sitemap_url)
sitemap.to_csv("sitemap.csv")
sitemap_df = pd.read_csv("sitemap.csv", index_col=False)
sitemap_df.drop(columns=["Unnamed: 0"], inplace=True)
sitemap_df
Above, the Complaintsboard.com sitemap has been taken into a Pandas data frame, and you can see the output below.
-
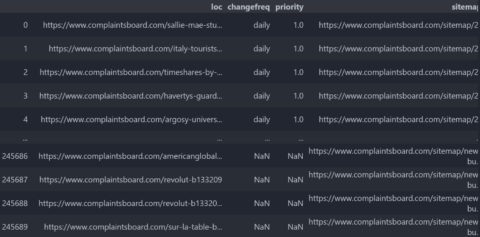 A General Sitemap URL Extraction with Sitemap Tags with Python is above.
A General Sitemap URL Extraction with Sitemap Tags with Python is above.
In total, we have 245,691 URLs in the sitemap index file of Complaintsboard.com.
The website uses “changefreq,” “lastmod,” and “priority” with an inconsistency.
3. Check Tag Usage Within The Sitemap XML File
To understand which tags are used or not within the Sitemap XML file, use the function below.
def check_sitemap_tag_usage(sitemap):
lastmod = sitemap["lastmod"].isna().value_counts()
priority = sitemap["priority"].isna().value_counts()
changefreq = sitemap["changefreq"].isna().value_counts()
lastmod_perc = sitemap["lastmod"].isna().value_counts(normalize = True) * 100
priority_perc = sitemap["priority"].isna().value_counts(normalize = True) * 100
changefreq_perc = sitemap["changefreq"].isna().value_counts(normalize = True) * 100
sitemap_tag_usage_df = pd.DataFrame(data={"lastmod":lastmod,
"priority":priority,
"changefreq":changefreq,
"lastmod_perc": lastmod_perc,
"priority_perc": priority_perc,
"changefreq_perc": changefreq_perc})
return sitemap_tag_usage_df.astype(int)
The function check_sitemap_tag_usage is a data frame constructor based on the usage of the sitemap tags.
It takes the “lastmod,” “priority,” and “changefreq” columns by implementing “isna()” and “value_counts()” methods via “pd.DataFrame”.
Below, you can see the output.
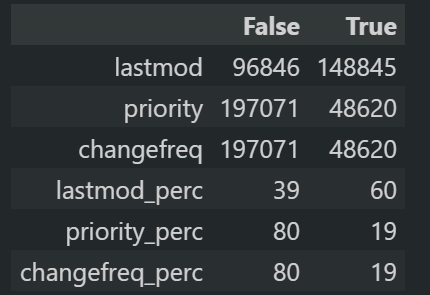 Sitemap Audit with Python for sitemap tags’ usage.
Sitemap Audit with Python for sitemap tags’ usage.The data frame above shows that 96,840 of the URLs do not have the Lastmod tag, which is equal to 39% of the total URL count of the sitemap file.
The same usage percentage is 19% for the “priority” and the “changefreq” within the sitemap XML file.
There are three main content freshness signals from a website.
These are dates from a web page (visible to the user), structured data (invisible to the user), “lastmod” in the sitemap.
If these dates are not consistent with each other, search engines can ignore the dates on the websites to see their freshness signals.
4. Audit The Site-tree And URL Structure Of The Website
Understanding the most important or crowded URL Path is necessary to weigh the website’s SEO efforts or technical SEO Audits.
A single improvement for Technical SEO can benefit thousands of URLs simultaneously, which creates a cost-effective and budget-friendly SEO strategy.
URL Structure Understanding mainly focuses on the website’s more prominent sections and content network analysis understanding.
To create a URL Tree Dataframe from a website’s URLs from the sitemap, use the following code block.
sitemap_url_df = adv.url_to_df(sitemap_df["loc"]) sitemap_url_df
With the help of “urllib” or the “advertools” as above, you can easily parse the URLs within the sitemap into a data frame.
-
Creating a URL Tree with URLLib or Advertools is easy.
- Checking the URL breakdowns helps to understand the overall information tree of a website.
The data frame above contains the “scheme,” “netloc,” “path,” and every “/” breakdown within the URLs as a “dir” which represents the directory.
Auditing the URL structure of the website is prominent for two objectives.
These are checking whether all URLs have “HTTPS” and understanding the content network of the website.
Content analysis with sitemap files is not the topic of the “Indexing and Crawling” directly, thus at the end of the article, we will talk about it slightly.
Check the next section to see the SSL Usage on Sitemap URLs.
5. Check The HTTPS Usage On The URLs Within Sitemap
Use the following code block to check the HTTP Usage ratio for the URLs within the Sitemap.
sitemap_url_df["scheme"].value_counts().to_frame()
The code block above uses a simple data filtration for the “scheme” column which contains the URLs’ HTTPS Protocol information.
using the “value_counts” we see that all URLs are on the HTTPS.
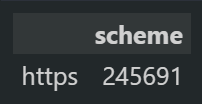 Checking the HTTP URLs from the Sitemaps can help to find bigger URL Property consistency errors.
Checking the HTTP URLs from the Sitemaps can help to find bigger URL Property consistency errors.6. Check The Robots.txt Disallow Commands For Crawlability
The structure of URLs within the sitemap is beneficial to see whether there is a situation for “submitted but disallowed”.
To see whether there is a robots.txt file of the website, use the code block below.
import requests
r = requests.get("https://www.complaintsboard.com/robots.txt")
R.status_code
200
Simply, we send a “get request” to the robots.txt URL.
If the response status code is 200, it means there is a robots.txt file for the user-agent-based crawling control.
After checking the “robots.txt” existence, we can use the “adv.robotstxt_test” method for bulk robots.txt audit for crawlability of the URLs in the sitemap.
sitemap_df_robotstxt_check = adv.robotstxt_test("https://www.complaintsboard.com/robots.txt", urls=sitemap_df["loc"], user_agents=["*"])
sitemap_df_robotstxt_check["can_fetch"].value_counts()
We have created a new variable called “sitemap_df_robotstxt_check”, and assigned the output of the “robotstxt_test” method.
We have used the URLs within the sitemap with the “sitemap_df[“loc”]”.
We have performed the audit for all of the user-agents via the “user_agents = [“*”]” parameter and value pair.
You can see the result below.
True 245690 False 1 Name: can_fetch, dtype: int64
It shows that there is one URL that is disallowed but submitted.
We can filter the specific URL as below.
pd.set_option("display.max_colwidth",255)
sitemap_df_robotstxt_check[sitemap_df_robotstxt_check["can_fetch"] == False]
We have used “set_option” to expand all of the values within the “url_path” section.
-
 A URL appears as disallowed but submitted via a sitemap as in Google Search Console Coverage Reports.
A URL appears as disallowed but submitted via a sitemap as in Google Search Console Coverage Reports. - We see that a “profile” page has been disallowed and submitted.
Later, the same control can be done for further examinations such as “disallowed but internally linked”.
But, to do that, we need to crawl at least 3 million URLs from ComplaintsBoard.com, and it can be an entirely new guide.
Some website URLs do not have a proper “directory hierarchy”, which can make the analysis of the URLs, in terms of content network characteristics, harder.
Complaintsboard.com doesn’t use a proper URL structure and taxonomy, so analyzing the website structure is not easy for an SEO or Search Engine.
But the most used words within the URLs or the content update frequency can signal which topic the company actually weighs on.
Since we focus on “technical aspects” in this tutorial, you can read the Sitemap Content Audit here.
7. Check The Status Code Of The Sitemap URLs With Python
Every URL within the sitemap has to have a 200 Status Code.
A crawl has to be performed to check the status codes of the URLs within the sitemap.
But, since it’s costly when you have millions of URLs to audit, we can simply use a new crawling method from Advertools.
Without taking the response body, we can crawl just the response headers of the URLs within the sitemap.
It is useful to decrease the crawl time for auditing possible robots, indexing, and canonical signals from the response headers.
To perform a response header crawl, use the “adv.crawl_headers” method.
adv.crawl_headers(sitemap_df["loc"], output_file="sitemap_df_header.jl")
df_headers = pd.read_json("sitemap_df_header.jl", lines=True)
df_headers["status"].value_counts()
The explanation of the code block for checking the URLs’ status codes within the Sitemap XML Files for the Technical SEO aspect can be seen below.
200 207866 404 23 Name: status, dtype: int64
It shows that the 23 URL from the sitemap is actually 404.
And, they should be removed from the sitemap.
To audit which URLs from the sitemap are 404, use the filtration method below from Pandas.
df_headers[df_headers["status"] == 404]
The result can be seen below.
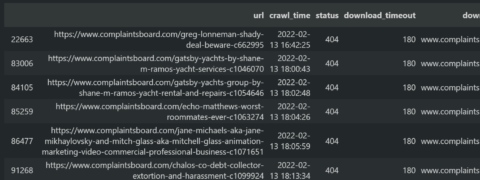 Finding the 404 URLs from Sitemaps is helpful against Link Rot.
Finding the 404 URLs from Sitemaps is helpful against Link Rot.8. Check The Canonicalization From Response Headers
From time to time, using canonicalization hints on the response headers is beneficial for crawling and indexing signal consolidation.
In this context, the canonical tag on the HTML and the response header has to be the same.
If there are two different canonicalization signals on a web page, the search engines can ignore both assignments.
For ComplaintsBoard.com, we don’t have a canonical response header.
- The first step is auditing whether the response header for canonical usage exists.
- The second step is comparing the response header canonical value to the HTML canonical value if it exists.
- The third step is checking whether the canonical values are self-referential.
Check the columns of the output of the header crawl to check the Canonicalization from Response Headers.
df_headers.columns
Below, you can see the columns.
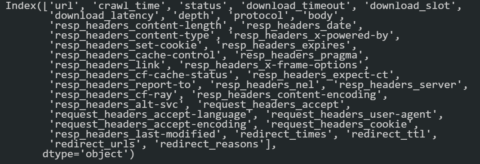 Python SEO Crawl Output Data Frame columns. “dataframe.columns” method is always useful to check.
Python SEO Crawl Output Data Frame columns. “dataframe.columns” method is always useful to check.If you are not familiar with the response headers, you may not know how to use canonical hints within response headers.
A response header can include the canonical hint with the “Link” value.
It is registered as “resp_headers_link” by the Advertools directly.
Another problem is that the extracted strings appear within the “<URL>;” string pattern.
It means we will use regex to extract it.
df_headers["resp_headers_link"]
You can see the result below.
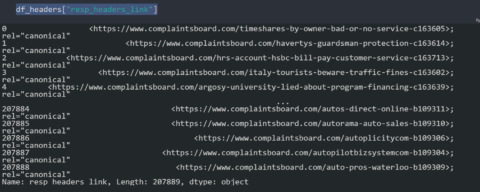 Screenshot from Pandas, February 2022
Screenshot from Pandas, February 2022The regex pattern “[^<>][a-z:\/0-9-.]*” is good enough to extract the specific canonical value.
A self-canonicalization check with the response headers is below.
df_headers["response_header_canonical"] = df_headers["resp_headers_link"].str.extract(r"([^<>][a-z:\/0-9-.]*)") (df_headers["response_header_canonical"] == df_headers["url"]).value_counts()
We have used two different boolean checks.
One to check whether the response header canonical hint is equal to the URL itself.
Another to see whether the status code is 200.
Since we have 404 URLs within the sitemap, their canonical value will be “NaN”.
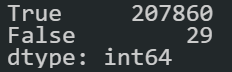 It shows there are specific URLs with canonicalization inconsistencies.
It shows there are specific URLs with canonicalization inconsistencies.- We have 29 outliers for Technical SEO. Every wrong signal given to the search engine for indexation or ranking will cause the dilution of the ranking signals.
To see these URLs, use the code block below.
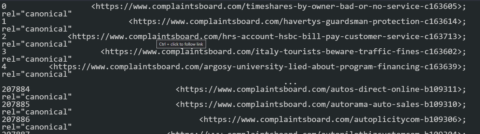 Screenshot from Pandas, February 2022.
Screenshot from Pandas, February 2022.The Canonical Values from the Response Headers can be seen above.
df_headers[(df_headers["response_header_canonical"] != df_headers["url"]) & (df_headers["status"] == 200)]
Even a single “/” in the URL can cause canonicalization conflict as appears here for the homepage.
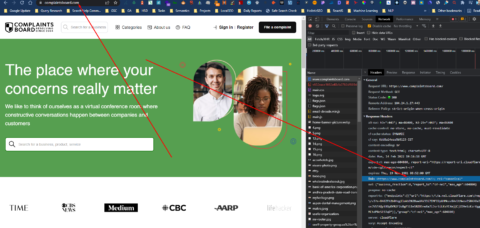 ComplaintsBoard.com Screenshot for checking the Response Header Canonical Value and the Actual URL of the web page.
ComplaintsBoard.com Screenshot for checking the Response Header Canonical Value and the Actual URL of the web page.- You can check the canonical conflict here.
If you check log files, you will see that the search engine crawls the URLs from the “Link” response headers.
Thus in technical SEO, this should be weighted.
9. Check The Indexing And Crawling Commands From Response Headers
There are 14 different X-Robots-Tag specifications for the Google search engine crawler.
The latest one is “indexifembedded” to determine the indexation amount on a web page.
The Indexing and Crawling directives can be in the form of a response header or the HTML meta tag.
This section focuses on the response header version of indexing and crawling directives.
- The first step is checking whether the X-Robots-Tag property and values exist within the HTTP Header or not.
- The second step is auditing whether it aligns itself with the HTML Meta Tag properties and values if they exist.
Use the command below yo check the X-Robots-Tag” from the response headers.
def robots_tag_checker(dataframe:pd.DataFrame):
for i in df_headers:
if i.__contains__("robots"):
return i
else:
return "There is no robots tag"
robots_tag_checker(df_headers)
OUTPUT>>>
'There is no robots tag'
We have created a custom function to check the “X-Robots-tag” response headers from the web pages’ source code.
It appears that our test subject website doesn’t use the X-Robots-Tag.
If there would be an X-Robots-tag, the code block below should be used.
df_headers["response_header_x_robots_tag"].value_counts() df_headers[df_headers["response_header_x_robots_tag"] == "noindex"]
Check whether there is a “noindex” directive from the response headers, and filter the URLs with this indexation conflict.
In the Google Search Console Coverage Report, those appear as “Submitted marked as noindex”.
Contradicting indexing and canonicalization hints and signals might make a search engine ignore all of the signals while making the search algorithms trust less to the user-declared signals.
10. Check The Self Canonicalization Of Sitemap URLs
Every URL in the sitemap XML files should give a self-canonicalization hint.
Sitemaps should only include the canonical versions of the URLs.
The Python code block in this section is to understand whether the sitemap URLs have self-canonicalization values or not.
To check the canonicalization from the HTML Documents’ “<head>” section, crawl the websites by taking their response body.
Use the code block below.
user_agent = "Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/W.X.Y.Z Mobile Safari/537.36 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)"
The difference between “crawl_headers” and the “crawl” is that “crawl” takes the entire response body while the “crawl_headers” is only for response headers.
adv.crawl(sitemap_df["loc"],
output_file="sitemap_crawl_complaintsboard.jl",
follow_links=False,
custom_settings={"LOG_FILE":"sitemap_crawl_complaintsboard.log", “USER_AGENT”:user_agent})
You can check the file size differences from crawl logs to response header crawl and entire response body crawl.
 Python Crawl Output Size Comparison.
Python Crawl Output Size Comparison.From 6GB output to the 387 MB output is quite economical.
If a search engine just wants to see certain response headers and the status code, creating information on the headers would make their crawl hits more economical.
How To Deal With Large DataFrames For Reading And Aggregating Data?
This section requires dealing with the large data frames.
A computer can’t read a Pandas DataFrame from a CSV or JL file if the file size is larger than the computer’s RAM.
Thus, the “chunking” method is used.
When a website sitemap XML File contains millions of URLs, the total crawl output will be larger than tens of gigabytes.
An iteration across sitemap crawl output data frame rows is necessary.
For chunking, use the code block below.
df_iterator = pd.read_json(
'sitemap_crawl_complaintsboard.jl',
chunksize=10000,
lines=True)
for i, df_chunk in enumerate(df_iterator):
output_df = pd.DataFrame(data={"url":df_chunk["url"],"canonical":df_chunk["canonical"], "self_canonicalised":df_chunk["url"] == df_chunk["canonical"]})
mode="w" if i == 0 else 'a'
header = i == 0
output_df.to_csv(
"canonical_check.csv",
index=False,
header=header,
mode=mode
)
df[((df["url"] != df["canonical"]) == True) & (df["self_canonicalised"] == False) & (df["canonical"].isna() != True)]
You can see the result below.
 Python SEO Canonicalization Audit.
Python SEO Canonicalization Audit.We see that the paginated URLs from the “book” subfolder give canonical hints to the first page, which is a non-correct practice according to the Google guidelines.
11. Check The Sitemap Sizes Within Sitemap Index Files
Every Sitemap File should be less than 50 MB. Use the Python code block below in the Technical SEO with Python context to check the sitemap file size.
pd.pivot_table(sitemap_df[sitemap_df["loc"].duplicated()==True], index="sitemap")
You can see the result below.
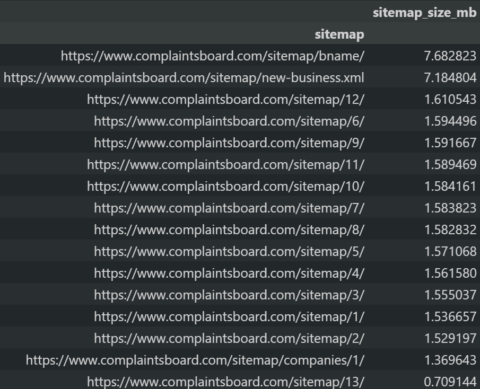 Python SEO Sitemap Size Audit.
Python SEO Sitemap Size Audit.We see that all sitemap XML files are under 50MB.
For better and faster indexation, keeping the sitemap URLs valuable and unique while decreasing the size of the sitemap files is beneficial.
12. Check The URL Count Per Sitemap With Python
Every URL within the sitemaps should have fewer than 50.000 URLs.
Use the Python code block below to check the URL Counts within the sitemap XML files.
(pd.pivot_table(sitemap_df, values=["loc"], index="sitemap", aggfunc="count") .sort_values(by="loc", ascending=False))
You can see the result below.
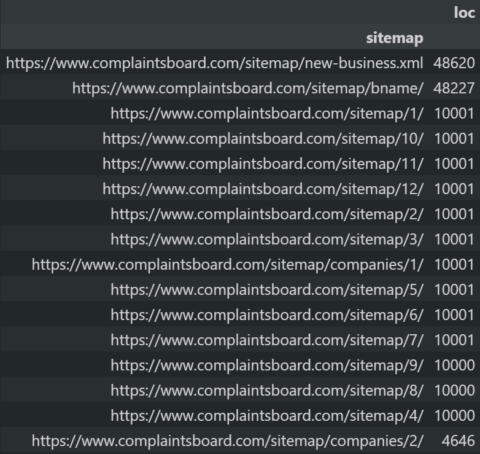 Python SEO Sitemap URL Count Audit.
Python SEO Sitemap URL Count Audit.- All sitemaps have less than 50.000 URLs. Some sitemaps have only one URL, which wastes the search engine’s attention.
Keeping sitemap URLs that are frequently updated different from the static and stale content URLs is beneficial.
URL Count and URL Content character differences help a search engine to adjust crawl demand effectively for different website sections.
13. Check The Indexing And Crawling Meta Tags From URLs’ Content With Python
Even if a web page is not disallowed from robots.txt, it can still be disallowed from the HTML Meta Tags.
Thus, checking the HTML Meta Tags for better indexation and crawling is necessary.
Using the “custom selectors” is necessary to perform the HTML Meta Tag audit for the sitemap URLs.
sitemap = adv.sitemap_to_df("https://www.holisticseo.digital/sitemap.xml")
adv.crawl(url_list=sitemap["loc"][:1000], output_file="meta_command_audit.jl",
follow_links=False,
xpath_selectors= {"meta_command": "//meta[@name="robots"]/@content"},
custom_settings={"CLOSESPIDER_PAGECOUNT":1000})
df_meta_check = pd.read_json("meta_command_audit.jl", lines=True)
df_meta_check["meta_command"].str.contains("nofollow|noindex", regex=True).value_counts()
The “//meta[@name=”robots”]/@content” XPATH selector is to extract all the robots commands from the URLs from the sitemap.
We have used only the first 1000 URLs in the sitemap.
And, I stop crawling after the initial 1000 responses.
I have used another website to check the Crawling Meta Tags since ComplaintsBoard.com doesn’t have it on the source code.
You can see the result below.
 Python SEO Meta Robots Audit.
Python SEO Meta Robots Audit.- None of the URLs from the sitemap have “nofollow” or “noindex” within the “Robots” commands.
To check their values, use the code below.
df_meta_check[df_meta_check["meta_command"].str.contains("nofollow|noindex", regex=True) == False][["url", "meta_command"]]
You can see the result below.
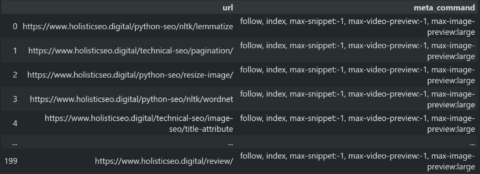 Meta Tag Audit from the Websites.
Meta Tag Audit from the Websites.14. Validate The Sitemap XML File Syntax With Python
Sitemap XML File Syntax validation is necessary to validate the integration of the sitemap file with the search engine’s perception.
Even if there are certain syntax errors, a search engine can recognize the sitemap file during the XML Normalization.
But, every syntax error can decrease the efficiency for certain levels.
Use the code block below to validate the Sitemap XML File Syntax.
def validate_sitemap_syntax(xml_path: str, xsd_path: str)
xmlschema_doc = etree.parse(xsd_path)
xmlschema = etree.XMLSchema(xmlschema_doc)
xml_doc = etree.parse(xml_path)
result = xmlschema.validate(xml_doc)
return result
validate_sitemap_syntax("sej_sitemap.xml", "sitemap.xsd")
For this example, I have used “https://www.searchenginejournal.com/sitemap_index.xml”. The XSD file involves the XML file’s context and tree structure.
It is stated in the first line of the Sitemap file as below.
For further information, you can also check DTD documentation.
15. Check The Open Graph URL And Canonical URL Matching
It is not a secret that search engines also use the Open Graph and RSS Feed URLs from the source code for further canonicalization and exploration.
The Open Graph URLs should be the same as the canonical URL submission.
From time to time, even in Google Discover, Google chooses to use the image from the Open Graph.
To check the Open Graph URL and Canonical URL consistency, use the code block below.
for i, df_chunk in enumerate(df_iterator):
if "og:url" in df_chunk.columns:
output_df = pd.DataFrame(data={
"canonical":df_chunk["canonical"],
"og:url":df_chunk["og:url"],
"open_graph_canonical_consistency":df_chunk["canonical"] == df_chunk["og:url"]})
mode="w" if i == 0 else 'a'
header = i == 0
output_df.to_csv(
"open_graph_canonical_consistency.csv",
index=False,
header=header,
mode=mode
)
else:
print("There is no Open Graph URL Property")
There is no Open Graph URL Property
If there is an Open Graph URL Property on the website, it will give a CSV file to check whether the canonical URL and the Open Graph URL are the same or not.
But for this website, we don’t have an Open Graph URL.
Thus, I have used another website for the audit.
if "og:url" in df_meta_check.columns:
output_df = pd.DataFrame(data={
"canonical":df_meta_check["canonical"],
"og:url":df_meta_check["og:url"],
"open_graph_canonical_consistency":df_meta_check["canonical"] == df_meta_check["og:url"]})
mode="w" if i == 0 else 'a'
#header = i == 0
output_df.to_csv(
"df_og_url_canonical_audit.csv",
index=False,
#header=header,
mode=mode
)
else:
print("There is no Open Graph URL Property")
df = pd.read_csv("df_og_url_canonical_audit.csv")
df
You can see the result below.
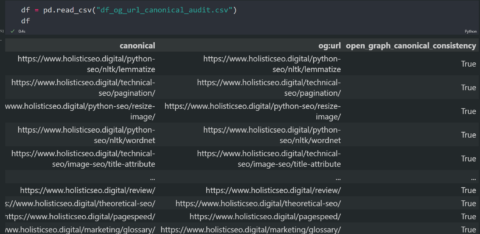 Python SEO Open Graph URL Audit.
Python SEO Open Graph URL Audit.We see that all canonical URLs and the Open Graph URLs are the same.

16. Check The Duplicate URLs Within Sitemap Submissions
A sitemap index file shouldn’t have duplicated URLs across different sitemap files or within the same sitemap XML file.
The duplication of the URLs within the sitemap files can make a search engine download the sitemap files less since a certain percentage of the sitemap file is bloated with unnecessary submissions.
For certain situations, it can appear as a spamming attempt to control the crawling schemes of the search engine crawlers.
use the code block below to check the duplicate URLs within the sitemap submissions.
sitemap_df["loc"].duplicated().value_counts()
You can see that the 49574 URLs from the sitemap are duplicated.
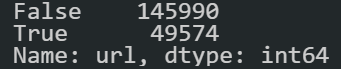 Python SEO Duplicated URL Audit from the Sitemap XML Files
Python SEO Duplicated URL Audit from the Sitemap XML FilesTo see which sitemaps have more duplicated URLs, use the code block below.
pd.pivot_table(sitemap_df[sitemap_df["loc"].duplicated()==True], index="sitemap", values="loc", aggfunc="count").sort_values(by="loc", ascending=False)
You can see the result.
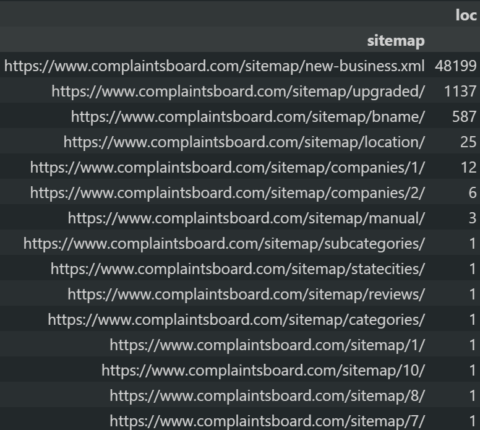 Python SEO Sitemap Audit for duplicated URLs.
Python SEO Sitemap Audit for duplicated URLs.Chunking the sitemaps can help with site-tree and technical SEO analysis.
To see the duplicated URLs within the Sitemap, use the code block below.
sitemap_df[sitemap_df["loc"].duplicated() == True]
You can see the result below.
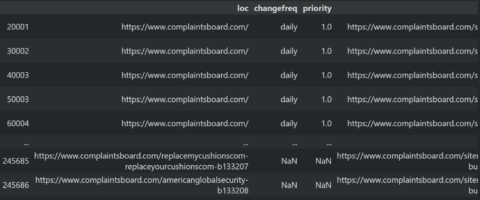 Duplicated Sitemap URL Audit Output.
Duplicated Sitemap URL Audit Output.Conclusion
I wanted to show how to validate a sitemap file for better and healthier indexation and crawling for Technical SEO.
Python is vastly used for data science, machine learning, and natural language processing.
But, you can also use it for Technical SEO Audits to support the other SEO Verticals with a Holistic SEO Approach.
In a future article, we can expand these Technical SEO Audits further with different details and methods.
But, in general, this is one of the most comprehensive Technical SEO guides for Sitemaps and Sitemap Audit Tutorial with Python.
More resources:
Featured Image: elenasavchina2/Shutterstock



